练习:当自变量为连续变量#
模型回顾#
在第十课的练习部分,我们探究了自我控制水平是否压力和吸烟有关,分别建立了三个回归模型,本节课的练习将基于上节课建立的三个模型进行。
💡 如果上节课的练习没有完成,是无法完成本节课的练习的哦!(难度 🔝🔝🔝)
| 模型 | model1 | model2 | model3 |
| 自变量 | 压力(连续变量) | 压力(连续变量),吸烟(离散变量)【无交互】 | 压力(连续变量),吸烟(离散变量)【有交互】 |
| 自变量含义 | 压力(14-70的压力评级);吸烟(`0` 表示不吸烟,`1` 表示吸烟) | ||
| 先验 | β0 ~ N(50, 10); β1 ~ N(0, 10); σ ~ Exp(0.6) | β0 ~ N(50, 10); β1 ~ N(0, 10); β2 ~ N(0, 10); σ ~ Exp(0.6) | β0 ~ N(50, 10); β1 ~ N(0, 10); β2 ~ N(0, 10); β3 ~ N(0, 10); σ ~ Exp(0.6) |
# 导入 pymc 模型包,和 arviz 等分析工具
import pymc as pm
import arviz as az
import seaborn as sns
import scipy.stats as st
import numpy as np
import matplotlib.pyplot as plt
import xarray as xr
import pandas as pd
import os
# 忽略不必要的警告
import warnings
warnings.filterwarnings("ignore")
# 通过 pd.read_csv 加载数据 Data_Sum_HPP_Multi_Site_Share.csv
try:
df_re = pd.read_csv('/home/mw/input/bayes3797/Data_Sum_HPP_Multi_Site_Share.csv')
except:
df_re = pd.read_csv('data/Data_Sum_HPP_Multi_Site_Share.csv')
# 筛选站点为"Tsinghua"的数据
df = df_re[df_re["Site"] == "Tsinghua"]
df = df[["stress","scontrol","smoke"]]
#1 表示吸烟,2表示不吸烟
df["smoke"] = np.where(df['smoke'] == 2, 0, 1)
df["smoke_recode"] = np.where(df['smoke'] == 1, "yes", "no")
#设置索引
df["index"] = range(len(df))
df = df.set_index("index")
##-------------------------------------------------
# 定义模型4、5、6,补全...部分
#---------------------------------------------------
with pm.Model() as model4:
beta_0 = pm.Normal("beta_0", mu=..., sigma=...)
beta_1 = pm.Normal("beta_1", mu=..., sigma=...)
sigma = pm.Exponential("sigma", ...)
x = pm.MutableData("smoke",df.stress)
mu = pm.Deterministic("mu", beta_0 + beta_1*x)
likelihood = pm.Normal("y_est", mu=mu, sigma=sigma, observed=df.scontrol)
with pm.Model() as model5:
beta_0 = pm.Normal("beta_0", mu=..., sigma=...)
beta_1 = pm.Normal("beta_1", mu=..., sigma=...)
beta_2 = pm.Normal("beta_2", mu=..., sigma=...)
sigma = pm.Exponential("sigma", ...)
stress = pm.MutableData("stress",df.stress)
smoke = pm.MutableData("smoke",df.smoke)
mu = pm.Deterministic("mu", beta_0 + beta_1*stress + beta_2*smoke)
likelihood = pm.Normal("y_est", mu=mu, sigma=sigma, observed=df.scontrol)
with pm.Model() as model6:
beta_0 = pm.Normal("beta_0", mu=..., sigma=...)
beta_1 = pm.Normal("beta_1", mu=..., sigma=...)
beta_2 = pm.Normal("beta_2", mu=..., sigma=...)
beta_3 = pm.Normal("beta_3", mu=..., sigma=...)
sigma = pm.Exponential("sigma", ...)
stress = pm.MutableData("stress",df.stress)
smoke = pm.MutableData("smoke",df.smoke)
mu = pm.Deterministic("mu", beta_0 +
beta_1*stress +
beta_2*smoke +
beta_3*stress*smoke)
likelihood = pm.Normal("y_est", mu=mu, sigma=sigma, observed=df.scontrol)
#========================================
# 注意!!!以下代码可能需要运行 5 分钟左右,直接运行即可
# 直接运行即可,无需修改
#========================================
def run_model_sampling(save_name, model=None, draws=2000, tune=1000, chains=4, random_seed=84735):
"""
运行模型采样,并在结果不存在时进行采样,存在时直接加载结果。
Parameters:
- save_name: 用于保存或加载结果的文件名(无扩展名)
- model: pymc 模型
- draws: 采样次数 (默认5000)
- tune: 调整采样策略的次数 (默认1000)
- chains: 链数 (默认4)
- random_seed: 随机种子 (默认84735)
Returns:
- trace: 采样结果
"""
# 检查是否存在保存的.nc文件
nc_file = f"{save_name}.nc"
if os.path.exists(nc_file):
print(f"加载现有的采样结果:{nc_file}")
# 如果文件存在,则加载采样结果
trace = az.from_netcdf(nc_file)
else:
assert model is not None, "模型未定义,请先定义模型"
print(f"没有找到现有的采样结果,正在执行采样:{save_name}")
# 如果文件不存在,则进行采样计算
with model:
trace = pm.sample_prior_predictive(draws=draws, random_seed=random_seed)
idata = pm.sample(draws=draws, # 使用mcmc方法进行采样,draws为采样次数
tune=tune, # tune为调整采样策略的次数
chains=chains, # 链数
discard_tuned_samples=True, # tune的结果将在采样结束后被丢弃
idata_kwargs={"log_likelihood": True},
random_seed=random_seed) # 后验采样
trace.extend(idata)
# 进行后验预测并扩展推断数据
pm.sample_posterior_predictive(trace, extend_inferencedata=True, random_seed=random_seed)
# 保存结果到指定文件
trace.to_netcdf(nc_file)
return trace
# 运行所有三个模型
model4_trace = run_model_sampling("lec10_model4",model4)
model5_trace = run_model_sampling("lec10_model5",model5)
model6_trace = run_model_sampling("lec10_model6",model6)
# 直接运行即可,无需修改
# 将3个模型中的inference data 中的 y_est 统一改为 Y_obs
model4_trace = model4_trace.rename({"y_est": "Y_obs"})
model5_trace = model5_trace.rename({"y_est": "Y_obs"})
model6_trace = model6_trace.rename({"y_est": "Y_obs"})
计算MAE#
# 直接运行即可,无需修改
def calculate_mae(trace, observed_data, dv = "Y_obs"):
"""
计算后验预测均值和 MAE (Median Absolute Error)。
Parameters:
- trace: PyMC 模型的采样结果 (InferenceData 对象)。
- observed_data: 包含真实观测值的 Pandas DataFrame。
- dv: 需要计算 MAE 的数据列名,默认为 "Y_obs"。
Returns:
- posterior_mean: 后验预测值的均值。
- mae: 后验预测均值与观测值之间的 MAE。
"""
# 提取后验预测值
posterior_predictive = trace.posterior_predictive[dv]
# 计算后验预测均值(在 draw 和 chain 两个维度上取平均值)
posterior_mean = posterior_predictive.mean(dim=["chain", "draw"])
# 计算 MAE(绝对误差的中位数)
mae = np.median(np.abs(observed_data - posterior_mean))
return mae
##================================================
# 练习,修改... 部分
#
#================================================
pd.DataFrame({
"Model 4": [calculate_mae(model4_trace, df["..."], "...")],
"Model 5": [calculate_mae(model5_trace, df["..."], "...")],
"Model 6": [calculate_mae(model6_trace, df["..."], "...")],
})
Model4 |
Model5 |
Model6 |
|
|---|---|---|---|
0 |
3.417442 |
3.525749 |
3.548162 |
计算elpd_loo#
##================================================
# 练习,修改... 部分
#================================================
comparison_list = {
"model4(contiunous)":...,
"model5(multivariate )":...,
"model6(interaction)":...,
}
az.compare(comparison_list)
计算DIC#
# 直接运行即可,无需修改
def calculate_dic(log_likelihood):
"""
根据 log-likelihood 计算 DIC (Deviance Information Criterion)。 参考 Evans, N. J. (2019). Assessing the practical differences between model selection methods in inferences about choice response time tasks. Psychonomic Bulletin & Review, 26(4), 1070–1098. https://doi.org/10.3758/s13423-018-01563-9
Parameters:
- log_likelihood: xarray 数据集,包含每个链和样本的 log-likelihood 值。
Returns:
- dic: 计算得到的 DIC 值。
"""
# 计算每个样本的Deviance
deviance_samples = -2 * log_likelihood
# 计算平均Deviance
D_bar = deviance_samples.mean()
# 计算有效自由度 p_D
p_D = deviance_samples.max() - D_bar
# 计算DIC
DIC = -2 * (D_bar - p_D)
return DIC["Y_obs"].values
##================================================
# 练习,修改... 部分
#
#================================================
DIC_list = {
"m4_dic_value":calculate_dic(...),
"m5_dic_value":calculate_dic(...),
"m6_dic_value":calculate_dic(...),
}
总结#
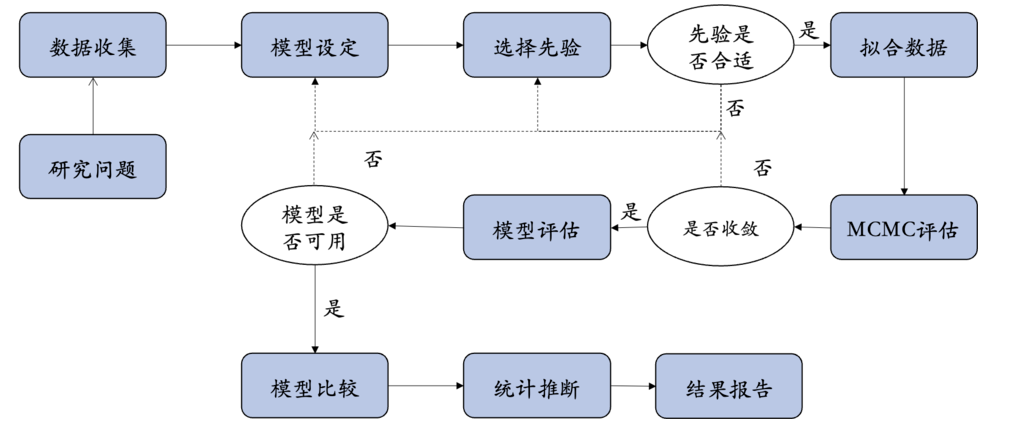
本节课从不同模型评估的角度,介绍了模型评估与比较的基本思想。
通过学习,我们对贝叶斯分析的整体流程(Bayesian workflow)有了初步的理解。
在接下来的课程中,我们将不断实践这一流程,帮助大家更深入地领略贝叶斯分析的独特魅力。